
ماشین بردار پشتیبان :
ماشین بردار پشتیبان یک متد برمبنای یادگیری ماشین است که اساس آن یادگیری با کمک اطلاعات است که داده ها را با کمک بردارهای پشتیبان که الگوهای داده ای را بیان می کنند کلاس بندی می کند[۱۳].
برای دسته بندی کردن داده ها به ۲ دسته باید تابع (f(X ای پیدا کنیم به طوری که Yi= f(Xi) که برای N داده به صورت (X1 , Y1) …. (Xi,yi) …….. (Xn,Yn) تابع f را بتوان به این صورت تعریف کرد :
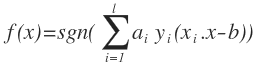
که در آن l تعداد رکوردهایی هستند که برای آموزش استفاده می شوند. {Yi ϵ {-۱,۱ و ai عددی مثبت و کوچکتر از عدد ثابت C است و Xi نیز بردار پشتیبان است.اما اگر تابعی که برای دسته بندی استفاده می شود خطی نشود ، باید داده ها را به ابعادی بالاتر ببریم تا تابع جدا کننده ی آن ها تابعی خطی بشود. برای این کار تبدیل به صورت زیر در می آید :
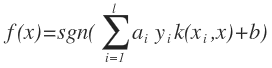
که در آن (k(Xi,X تابع هسته نامیده می شود که همان تابعی است که برای بردن داده ها به بعد بالاتر از آن استفاده می شود.
مدل ارتقاء یافته ماشین بردار پشتیبان [۱۳]:
تابع هسته که در قسمت قبل معرفی شد می تواند انواع مختلفی داشته باشد و به دسته های مختلفی تقسیم شود که به علت پیچیدگی ریاضی بالا بیان آن ها مشکل است. بیشتر انواع توابع هسته به صورت خطی هستند و تفاوتی میان خصوصیت های مختلف داده ها قائل نمی شوند. مثلا تابعی که در قسمت قبل بیان شد نیز یک تابع خطی است که همین خصوصیت را دارد که در آن با همه خصوصیات داده ها به طور یکسان رفتار می شود. این یکسان بودن رفتار کارایی را پایین آورده و بر روی دقت ماشین بردار پشتیبان اثر منفی می گذارد. راه حلی که برای این کار به نظر می رسد این است که برای تابع هسته وزن در نظر بگیریم. این وزن ها برای تعیین اثر خصوصیت ها به کار می روند. حالت کلی تابع جدیدی که برای این کار در نظر می گیریم به صورت (k(WXi,X است ، که در آن W برداری است که شامل وزن خصوصیت ها می باشد.
به این ترتیب تابع کلی به صورت زیر در می آید :
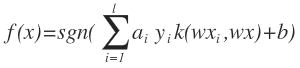
حالا نتیجه ی آزمایش انجام شده روی ماشین بردار پشتیبان معمولی و ارتقاء یافته را نشان می دهیم [۱۳] :
در این آزمایش نیز مثل آزمایش های قبل و بعد از مجموعه داده های KDD استفاده شده است. که به علت وجود توضیحات در سایر آزمایش ها از توضیح آن خودداری می کنیم. در این آزمایش از ۱۰ درصد این داده ها استفاده شده که ۱٫۵ درصد آن ها مربوط به نفوذ ها و بقیه مربوط به داده های معمولی و غیر نفوذ است. برای این آزمایش یک مجموعه داده آموزشی به همراه ۳ مجموعه برای تست که همگی زیر مجموعه ی مجموعه داده های اصلی هستند در نظر گرفته شده است.
مفاهیمی که در جدول از آن ها استفاده شده در آزمایش قبلی (درخت تصمیم) شرح داده شده است. نتایج به صورت زیر است :
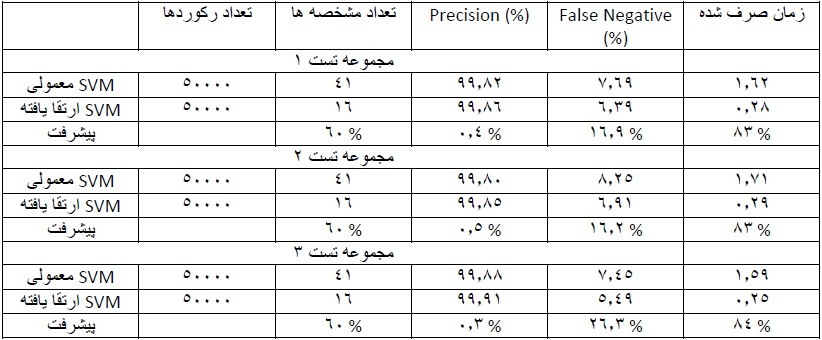
همان طور که در نتایج مشاهده می شود استفاده از ماشین بردار پشتیبان ارتقا یافته بیشتر از ۸۰ درصد زمان بررسی داده ها را کاهش داده است! علاوه بر آن دقت تشخیص را نیز تا مقدار قابل توجهی بالا برده است. که از نظر تئوری هم همان طور که بیان شد این نتیجه کاملا قابل پیش بینی بود. چرا که در نظر گرفتن اهمیت و وزن خصوصیات داده ها یک مزیت بسیار اثرگذار است که در مقابل رفتار یکسان با همه خصوصیت ها قرار می گیرد.
مقایسه ی نتایج حاصل از دو روش درخت تصمیم و ماشین بردار پشتیبان بر روی داده های یکسان :
در این آزمایش از مجموعه داده های KDD99 استفاده شده است که داده های خام و مخرب TCP در طول ۹ هفته می باشد. مجموعه ی داده ها به ۲۴ نوع حمله (نفوذ) تقسیم بندی می شوند که این حمله ها نیز خود به ۴ دسته اصلی تقسیم می شوند [۱۲].
۱- حملات Dos : در این حمله ها با ایجاد درخواست بیش از و به کارگرفته شدن بیش از حد منابع حافظه ای باعث اختلال در سیستم می شوند.
۲-حملات Remote to User: در این نوع حملات نفوذگر در ماشین هدف اکانتی ندارد ، بنابراین با فرستادن پکت هایی در شبکه و با استفاده از آسیب پذیری ها به عنوان کاربر آن سیستم وارد می شود!
۳-حملات User to Root : در این نوع حمله نفوذگر به یک اکانت معمولی دسترسی پیدا می کند و سپس با استفاده از نقاط آسیب پذیر به عنوان ریشه یا همان root دسترسی پیدا کرده و سیستم را در دست می گیرد.
۴-حملات Probing: در این نوع نفوذ ، نفوذگر با بررسی مداوم شبکه به نقاط آسیب پذیر یک سیستم پی می برد و با استفاده از آن ها به سیستم آسیب می زند.
یکی از نکات مهم انتخاب خصوصیت هایی است که می خواهیم آن ها را مورد بررسی قرار دهیم. این خصوصیات انواع مختلفی دارند. مثلا خصوصیت هایی که ارتباط هایی را بررسی می کنند که در ۲ ثانیه گذشته دارای مقصد مشترکی بوده اند. یا ارتباط هایی که در ۲ ثانیه گذشته سرویس مشترکی را داشته اند. بعضی دیگر نیز به دنبال خصوصیات رفتاری خاصی می گردند. مانند تعداد تلاش ناموفق برای ورود سیستم در یک زمان محدود.
اما برای تست یک روش تشخیص نفوذ مجموعه ی داده ای ۲ قسمت می شود. تعدادی از آن ها که به صورت اتفاقی نیز انتخاب می شوند برای آموزش آن سیستم استفاده شده و بقیه برای تست استفاده می شوند. مثلا در آزمایش فعلی از حدود ۱۱۹۸۲ رکورد ۵۰۹۲ رکورد برای آموزش و ۶۸۹۰ رکورد برای تست استفاده می شوند.
هدف اصلی از این سیستم تشخیص نفوذ این است که تمامی این داده ها به ۴ کلاس حمله که در بالا در مورد ۴ نوع آن توضیح داده شد و یک کلاس معمولی که همان موارد بی خطر یا معمولی است تقسیم بندی شوند. در واقع ما ۵ کلاس داریم که داده ها باید در یکی از این کلاس ها قرار گیرند.
روند کلی کار شامل ۲ مرحله است که در ابتدا داده هایی برای آموزش سیستم به صورت تصادفی انتخاب می شوند که تعداد آن ها را در بالا ذکر کردیم. پس از این که سیستم آموزش لازم را دید باید به وسیله ی سایر داده ها آزموده شده و دقت آن در کلاس بندی داده های باقیمانده مورد ارزیابی قرار گیرد.
نتایج مربوط به درخت تصمیم :
به صورت کلی هر کلاس بندی کننده (در این جا درخت تصمیم یا ماشین بردار پشتیبان) با داده های آموزشی ایجاد خواهد شد و هر داده به ترتیب با هر کدام از کلاس ها بررسی خواهد شد. هر کلاسی داده را به یکی از دسته های عادی یا حمله می دهد. طبیعی است که اگر کلاسی یک داده را در حالت معمولی قرار داد یعنی این که آن داده حداقل حمله ای از نوع آن کلاس نیست!
نتایج به دست آمده برای درخت تصمیم به این صورت است [۱۲]:

نتایج مربوط به ماشین بردار پشتیبان [۱۲]
برای ماشین بردار پشتیبان هم موارد ذکر شده در بخش بالا (درخت تصمیم) برقرار است. نتایج به دست آمده به این صورت است :

در این ماشین بردار پشتیبان از تابع هسته ی درجه ای استفاده شده است (که در قسمت ماشین بردار پشتیبان توضیح آن ارائه شد) که چون در هر مورد می توان درجه های مختلف را بررسی کرده و نتایج مختلف گرفت نتایج به دست آمده از درجه های مختلف را این گونه نشان می دهیم [۱۲]:

مقایسه بین نتایج درخت تصمیم و ماشین بردار پشتیبان :
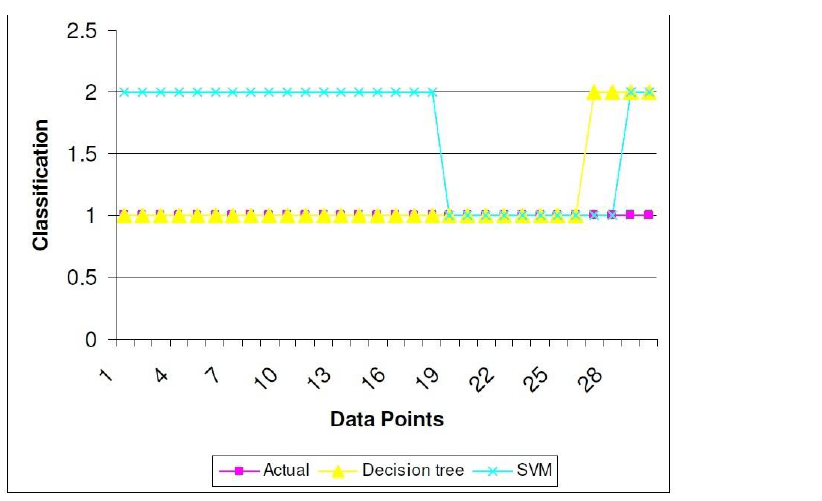
درخت تصمیم در ۳ مورد Probe , R2L , U2R دارای دقت بهتری بود در حالی که در مورد حملات DOS ماشین بردار پشتیبان دقت بهتری داشت. در مورد داده های Normal دقت مشابه بود. نکته مهمی که از نتایج به دست می آید این است که فاصله ی دقت این دو روش در ۲ کلاس U2R , R2L زیاد است و درخت تصمیم با فاصله ی زیادی عملکرد بهتری دارد. همان طور که می دانیم این دو روش ذکر شده دارای آموزش کمتری نسبت به سایرین هستند بنابراین می توان نتیجه گرفت که درخت تصمیم با مجموعه داده های آموزشی کوچکتر نتایج خیلی بهتری ارائه می دهد.نمودار زیر هم کارایی درخت تصمیم و ماشین بردار پشتیبان را در مورد کلاس R2L نشان می دهد که واضح است که کارایی درخت تصمیم تا چه حد بهتر از ماشین بردار پشتیبان بوده است. در این نمودار از ۳۰ نقطه داده ای برای نشان دادن کارایی ها استفاده شده است.
ادامه مقاله در روزهای آتی









{kind=link}
{kind=link}
دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.