
ماشین های بردار پشتیبان
ماشین های بردار پشتیبان خصیصه های ورودی با مقادیر حقیقی را با نگاشت غیرخطی به فضایی با ابعاد بالاتر می برد و با قرار دادن یک مرز خطی، داده ها را جدا می کند. پیدا کردن یک مرز تفکیک برای جدا سازی داده ها به مسئله بهینه سازی درجه دوم تبدیل می شود و از مرز خطی برای تقسیم بندی استفاده می شود. اما همه مسائل به از ویژگی به نام توابع پایه SVM صورت خطی قابل تفکیک نیستند و برای حل این مشکل استفاده می کند. این توابع الگوریتم های خطی را به غیرخطی تبدیل می کند و با بردن داده ها به فضایی با ابعاد بالاتر، تفکیک خطی را در آن فضا ممکن می سازند [۷].
این الگوریتم شامل مراحلی با عملیات های ریاضی است لذا با توضیحات ارائه شده شاید کمی گنگ به نظر بیاید. اما نگران نباشید در بخش آزمایش ها به جزئیات پیاده سازی و انجام مرحله به مرحله آن خواهیم پرداخت و عملیات آن را به صورت کامل و با مثال توضیح خواهیم داد.
درخت تصمیم
“درخت تصمیم یکی از روش های دسته بندی در حوزه داده کاوی است. در این بخش الگوریتمی ارائه می شود که با ساختن یک درخت تصمیم روی مجموعه ای از الگوها یا امضاهای شناخته شده از حملات، تعداد مقایسه های لازم برای شناسایی یک فعالیت مخرب را به نحو چشمگیری کاهش دهد [۷] اگر ما یک الگوی نفوذ را در پایگاه داده های خود ذخیره کرده باشیم ، مجموعه خصوصیات این الگو می تواند معیاری برای بررسی سایر فعالیت ها باشد. حالا اگر داده های ورودی را بررسی کنیم و آن را با قانون های موجود و خصوصیات که در پایگاه داده موجود است مقایسه کنیم و این داده های ورودی با تمام آن خصوصیات مطابقت داشته باشند داده ورودی با الگوی متناظر با قانون منطبق است. مجموعه این خصوصیات گره ریشه درخت را تشکیل می دهند. حال اگر یک ویژگی را انتخاب کرده و مقدار آن را در قانونی تعیین کنیم می توان زیر مجموعه های مختلفی از قوانین تشکیل داد که گره های دیگر درخت را تشکیل می دهند.
مسئله اصلی در ساخت درخت تصمیم، انتخاب ویژگی یا صفتی است که به نحو مناسب داده ها را در کلاسهای مربوطه دسته بندی نماید. هر درخت تصمیم شامل نود، یال و برگ است. نودهای درخت معادل صفاتی است عملیات دسته بندی داده را بر اساس مقادیر آن صفات انجام می دهیم. یال ها با مقادیری که هر صفت برای یک زیرمجموعه خاص از داده ها دارد برچسب می خورد و برگ ها معادل.کلاسی است که بخشی از داده ها در آن قرار می گیرند [۷] .
درختهای تصمیم روشی برای نمایش یک سری از قوانین هستند که منتهی به یک رده یا مقدار میشوند.درختهای تصمیمی که برای پیش بینی متغیرهای دسته ای استفاده میشوند، درختهای classification نامیده میشوند زیرا نمونه ها را در دسته ها یا رده ها قرار میدهند. درختهای تصمیمی که برای پیش بینی متغیرهای یپیوسته استفاده میشوند درختهای regression نامیده میشوند[۸] .
از دیگر مزایای درخت تصمیم عبارتند از [۹] :
· درخت تصمیم از نواحی تصمیم گیری ساده استفاده میکند.
· مقایسه های غیر ضروری در این ساختار حذف میشوند.
· آمادهسازی دادهها برای یک درخت تصمیم ساده یا غیر ضروری است.
· درختهای تصمیم قادر به شناسایی تفاوتهای زیرگروه ها میباشد.
با توجه به این که روش های معمول موجود برای تشخیص نفوذ در فاز قبل توضیح داده شد ، در این فاز و فاز بعد می خواهیم پرکاربردترین و بهترین این روش ها را با جزئیات بیشتری توضیح داده و تا حد ممکن با یکدیگر مقایسه کنیم.
در فاز ۲ درخت تصمیم و ماشین بردار پشتیبان را ابتدا هر کدام به صورت انفرادی و همراه با نتایج بررسی کرده ،سپس با ارائه نتایج چند آزمایش انجام شده نتایج استفاده از این ۲ را در سیستم های تشخیص نفوذ مقایسه می کنیم و در نهایت کارهای مرتبطی که در آن ها از این ۲ به صورت ترکیبی استفاده شده را بررسی می کنیم. ضمن این که در این فاز به مفهوم کاهش ویژگی که در تشخیص نفوذ بسیار اهمیت دارد نیز می پردازیم.
در فاز ۳ (اگر عمری بود و باز هم به لطف دوستان نمره صفر نگرفتیم!!) به بررسی شبکه عصبی ، الگوریتم ژنتیک و روش بیز و مقایسه ی کلی این چند روش با هم می پردازیم. امیدوارم در پایان این ۳ فاز و با بررسی روش های ذکر شده که تقریبا شامل تمامی روش های کاربردی و معروف تشخیص نفوذ می شوند تا حد خوبی بررسی شده باشند.
نکته ی دیگر این که تقریبا سعی شد تمام رابطه و فرمول هایی که در مقاله ها گفته شده در این متن آورده شود اما تعداد بسیار کمی آورده نشده که به ۲ دلیل بوده است. اول این که احساس می شد این روابط ربطی به موضوعات الگوریتمی و موضوع کلی بحث ندارد و صرفا محاسباتی برای پیدا کردن مقدار برخی متغیرهاست و دوم این که خود بنده (نویسنده) با وجود تلاش زیاد نتوانستم آن را به طور کامل درک کنم و طبیعتا از استفاده ی این فرمول ها که تعدادشان بسیار کم (در حد ۳ یا ۴) بود در متن این پروژه خودداری کردم.
درخت تصمیم:
درخت تصمیم به عنوان یک “مدل پیش بینی کننده بر اساس یادگیری ماشین و آمارها به منظور ایجاد یک ساختار درختی برای مدل کردن الگوهای داده ای” معرفی می شود. در واقع درخت های تصمیم مثال بارزی از الگوریتم کلاس بندی داده ها هستند. کلاس بندی روشی است که در آن هر کدام از داده ها به یکی از الگوهای تعیین شده نسبت داده می شوند[۱۰].
مثلا درخت تصمیم در حوزه ی تشخیص نفوذ می تواند داده های شبکه را به کلاس های مخرب ، و یا هر مدل دلخواه دیگری تقسیم بندی کند.
در واقع الگوریتم کلاس بندی مقدمه ای برای ساخت درخت است، به این ترتیب که با پیدا کردن الگوهای خاص در مجموعه ی داده ها درخت ها را ایجاد می کند. در شکل زیر مثالی از کلاس بندی و ایجاد یک خروجی به صورت درخت مشاهده می شود.
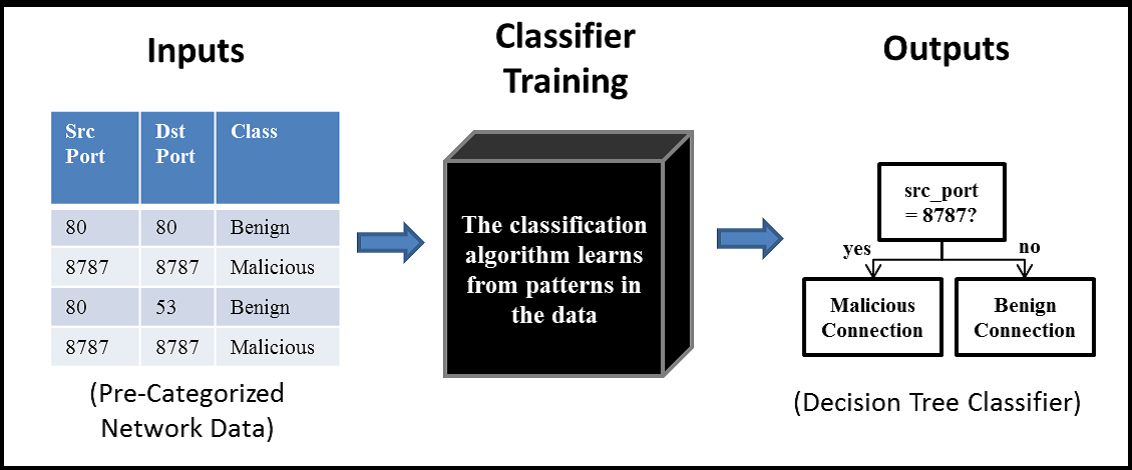
آن چه که در شکل به عنوان ورودی مشاهده می کنید مشخصات داده ها هستند که این مشخصات عامل دسته بندی داده ها می باشند. مشخصات داده ها می توانند گسسته یا پیوسته باشند و برای نگهداری آن ها می توان مانند تصویر بالا از جداول و یا پایگاه داده ها و یا هر گونه فایل قابل قسمت بندی استفاده کرد.
به طور کلی ساختن یک درخت کاملا بهینه نشدنی است چرا که با افزایش خصوصیاتی در داده ها که برای ما مهم باشند تعداد حالات تولید درخت ها به صورت نمایی افزایش پیدا می کند. به همین خاطر انواع مختلفی از درخت ها وجود دارد که در جدول زیر ۳ کلاس بندی کننده مختلف از درخت های تصمیم را با خصوصیات آن ها مشاهده می کنید
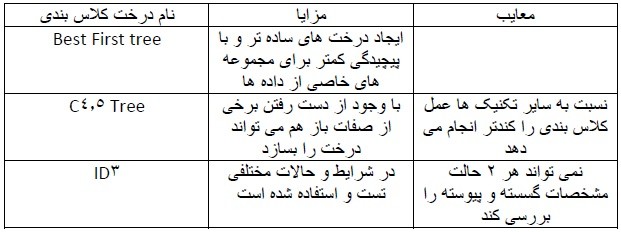
کته ای که در مورد مقایسه ی این درخت ها وجود دارد این است که نمی توان به طور مطلق یکی را برتر از دیگران دانست. در واقع در شرایط مختلف و در مورد مجموعه ی داده های مختلف درخت های متفاوتی می توانند بهترین نتایج را ارائه دهند.
کلاس بندی های که درخت های تصمیم انجام می دهند می توانند یک گروه را برای این که کدام الگوها را نگه داری کنند ، کدام روش های دیوار آتش را پیاده سازی کنند و یا کدام فعالیت ها را در شبکه برای آنالیز کردن نشانه گذاری کنند کمک می کنند اما مانند دیوار آتش یا سیستم های جلوگیری از نفوذ (IPS) نمی توانند به تنهایی نمی توانند عملیاتی برای مقابله با نفوذ انجام دهند.
حالا می خواهیم اجزای درخت های تصمیم را با جزئیات بیشتری بررسی کنیم :
یک درخت تصمیم از ۳ بخش اصلی تشکیل شده است :
۱- گره تصمیم ۱ که نمایانگر یک صفت یا خصوصیت قابل تست است.
۲- یال که بیانگر مقدار یک صفت یا به طور واضح تر خروجی تست آن صفت است.
۳- برگ که همان گره پاسخ نامیده شده و بیانگر کلاسی است که شیء به آن تعلق دارد.
الگوریتم های مختلفی برای تولید درخت تصمیم معرفی شدند که در جدول بالا ۳ نمونه به طور اختصاری بررسی شدند. اما برای انتخاب روش مناسب برای ساخت یک درخت تصمیم پارامترهای مختلفی وجود دارد :
۱- معیار انتخاب صفت مناسب :
همان طور که گفته شد گره تصمیم بیانگر یک صفت است. این که کدام صفت را برای قرار گرفتن در گره ریشه ی درخت یا زیر درخت قرار دهیم نیاز به تعیین یک معیار مناسب برای مشخص شدن توان هر گره برای انتخاب شدن دارد.
معیارهای مختلفی برای این کار وجود دارد که ما به توضیح آن چه برای درخت C4.5 تعیین شده است می پردازیم. این معیار gain ratio نام دارد. ورودی های این تابع یک صفت به نام A و یک مجموعه از اشیاء با نام T است. این تابع به این صورت تعریف می شود :
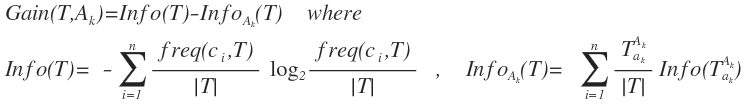
که در آن Ci تعداد اشیاء موجود در T است که به Ci تعلق دارد. و
![]()
زیر مجموعه ای از اشیاء است که در آن مشخصه ی Ak دارای مقدار ak است. و سپس مقدار مشخصات مشخصه ی Ak از رابطه ی زیر به دست می آید :
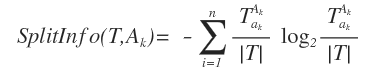
و در نهایت Gain Ratio با این رابطه و با درجه بندی شدن توسط رابطه ی بالا این گونه نوشته می شود :
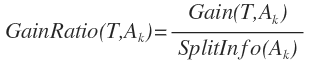
همین مورد در درخت ID3 این گونه بیان می شود :
اغلب الگوریتم های یادگیری درخت تصمیم بر پایه یک عمل جستجوی حریصانه بالا به پائین در فضای درختهای موجود عمل میکنند. در درخت تصمیم (ID3) از یک مقدار آماری به نام بهره اطلاعات Information Gain استفاده می شود تا اینکه مشخص کنیم که یک ویژگی تا چه مقدار قادر است مثالهای آموزشی را بر حسب دسته بندی آنها جدا کند [۹]. آنتروپی: [۹] میزان خلوص (بی نظمی یا عدم خالص بودن) مجموعه ای از مثالها را مشخص می کند. اگر مجموعه S شامل مثالهای مثبت و منفی از یک مفهوم هدف باشد آنتروپی S نسبت به این دسته بندی بولی بصورت زیر تعریف می شود :
![]()
بهره اطلاعات [۹] (Information Gain) بهره اطلاعات یک ویژگی عبارت است از مقدار کاهش آنتروپی که بواسطه جداسازی مثالها از طریق این ویژگی حاصل میشود. بعبارت دیگر بهره اطلاعات (Gain(S,A برای یک ویژگی نظیر A نسبت به مجموعه مثالهای S بصورت زیر تعریف میشود:
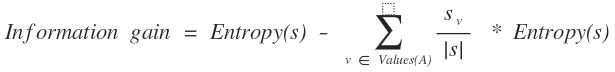
که در آن (Values A) مجموعه همه مقدار ویژگی های A بوده و VS زیرمجموعه ای از S است که برای آن A دارای مقدار V است. در تعریف فوق عبارت اول مقدار آنتروپی داده ها و عبارت دوم مقدار آنتروپی مورد انتظار بعد از جداسازی داده هاست
۲- استراتژی تقسیم بندی :
روشی که در آن اعضای مجموعه ای که در مورد ۱ ذکر شد را به کلاس صفت مناسب نسبت دهد.
۳- محدوده ی توقف :
این مورد تعیین کننده ی شرایطی است که با به وجود آمدن آن ادامه ی گسترش یک زیر درخت (و یا کل درخت) متوقف شود و در واقع زمان توقف ادامه ی تقسیم بندی مجموعه را بیان می کند. در واقع عملیات مقدار دهی به گره ها و یال ها در یک زیر درخت آنقدر ادامه پیدا می کنید تا همه ی داده ها در آن زیر درخت به یک کلاس تعلق پیدا کنند.
برای اضافه کردن اطلاعات به درخت تصمیم هر داده از ریشه شروع کرده و به گره ها می رود. در هر گره بررسی می شود که این داده به کدام کلاس مربوط است. این عمل آنقدر تکرار می شود تا به یک گره برگ برسیم. در آنجا برگی که این داده به آن تعلق پیدا کند محلی است که باید به آن جا اضافه شود.
ارتباط درخت تصمیم با سیستم های تشخیص نفوذ :
به طور خلاصه اگر بخواهیم فواید درخت تصمیم را برای سیستم های تشخیص نفوذ توضیح دهیم می توانیم فرآیندهای زیر را که به این سیستم ها کمک می کنند نام ببریم [۱۰]:
- استفاده به همراه روش ظرف عسل (Honey pot) که در آن یادگیری روش و تکنیک های نفوذ گران انجام شده و در شناسایی فعالیت های مخرب در شبکه کمک می کند.
به طور خلاصه تکنیک ذکر شده به این صورت است که به راحتی اجازه ی نفوذ را به نفوذگر می دهد و وی با فرض راحت بودن این کار ردپایی از خود به جا می گذارد که پیدا کردن این ردپا دقیقا همان هدف این تکنیک است.
- کمک در تست های نفوذ با یاد گرفتن روش ها از تست کننده ها و پیدا کردن روش هایی برای شناخت روش های تست تست کننده ها.
- شناخت و برجسته کردن ترافیک مخرب و مشکوک در شبکه
- اولویت بندی کردن هشدارها با مشخص کردن هشدارهای با ارزش و اولویت کمتر.
- نشانه گذاری روش های نفوذی که مکررا از آن ها استفاده می شود
- شناسایی رفتارهای غیر عادی در شبکه که در فاز ۱ در مورد آن ها توضیحات و مثال هایی ارائه شد
- پشتیبانی و کمک به افزایش اطلاعات سیستم تشخیص نفوذ با پیدا کردن روش های تشخیص فعالیت های مخرب
پس از این که درخت تصمیم ساخته شد ، می تواند حجم داده های موجود را کاهش دهد. در واقع داده هایی که به عنوان مخرب شناسایی نشده اند می توانند به خاطر بی خطر بودنشان حذف شوند. این کم کردن حجم اطلاعات یک کارایی بسیار مهم برای درخت تصمیم است.
در واقع کاری که یک درخت تصمیم در یک سیستم امنیتی انجام می دهد مشابه نشانه ی هدف گیری در یک اسلحه است که هدف را به تیرانداز نشان می دهد و سایر اجزا مانند خود سیستم تشخیص و جلوگیری نفوذ و دیوار آتش مانند اجزای شلیک تفنگ عمل می کنند.
هنگامی که روش یک نفوذ پیچیده شده و تعداد متغیرها و خصوصیت ها افزایش پیدا می کند روش های سیستماتیک مثل درخت تصمیم می تواند از این پیچیدگی کاسته و عملیات مخرب را شناسایی کند. یکی از مزیت های مهم درخت تصمیم نسبت به سایر روش ها ایجاد قوانینی کاملا شفاف ، قابل فهم و ساده برای پیاده سازی در سیستم های دارای محدودیت زمانی مثل تشخیص نفوذ و یا دیوار آتش است.
یکی دیگر از بزرگترین قابلیت های درخت تصمیم این است که تشخیص می دهد که روش های برخی از حملات زیرمجموعه ای از روش های دیگری است که در آموزش های قبلی فراگرفته است و این در تشخیص روش بسیاری از نفوذها مناسب است[۱۲].
پیاده سازی درخت تصمیم برای تشخیص نفوذ :
نخستین کاری که باید انجام شود این است که داده ها و ابزارهای موجود که دریافت می کنیم باید پیش پردازش شوند. این پیش پردازش باید داده ها را به فرمی در آورد که درخت تصمیم بتواند از آن ها استفاده کند. در واقع داده های خام و پردازش نشده نمی تواند به عنوان ورودی درخت تصمیم مورد استفاده قرار گیرد!
نتیجه پردازش داده ها برای مرحله بعد که تعیین مجموعه قوانین است بسیار مهم است. در مرحله ی بعد آنالیز روی این داده ها انجام شده و از نتیجه ای آن برای تعیین قوانین تصمیم گیری استفاده می شود. شکل زیر مراحل کار درخت تصمیم را نشان می دهد [۱۰]:
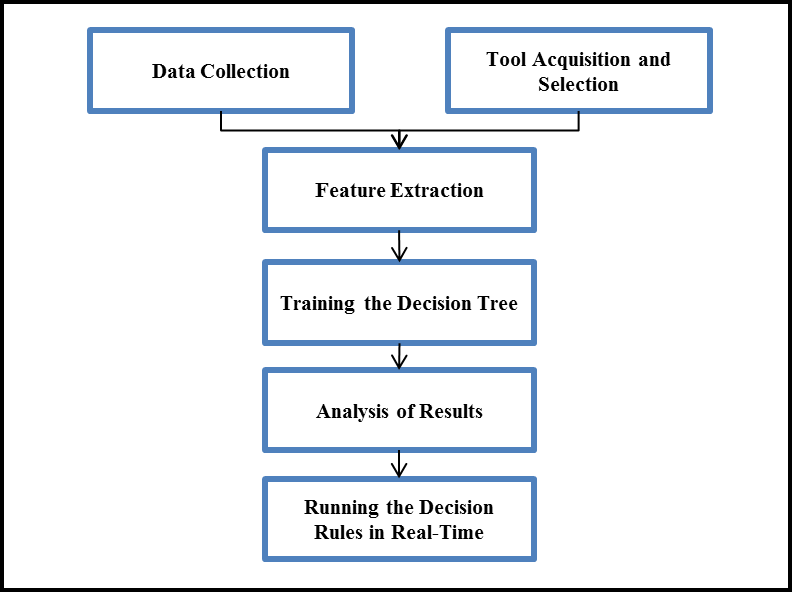
گرد آوری داده ها :
گرد آوری داده ها یکی از زمان بر ترین و مهم ترین کارها برای استفاده از یک روش مانند درخت تصمیم است. روشی که برای گردآوری داده ها انتخاب می شود باید به عملیاتی که تیم تشخیص نفوذ از درخت تصمیم انتظار دارند مربوط باشد. به عنوان مثال اگر درخت تصمیمی قرار است داده های مخرب را از بی خطر تشخیص دهد باید دو مجموعه داده که یکی شامل داده های نمونه ی مخرب و دیگری شامل داده های نمونه ی بی خطر است در اختیار داشته باشد. پیدا کردن و تقسیم بندی چنین داده هایی می تواند بزرگترین دغدغه برای پیاده سازی این تکنیک باشد.
برای جمع آوری داده ها نیز می توان از روش های زیر استفاده کرد [۱۰]:
- ظرف های عسل که توضیحاتی در مورد آن ها داده شد منبع بسیار خوبی برای جمع آوری داده ها هستند چرا که آن ها با فراهم کردن امکان نفوذ برای نفوذگر باعث به جا ماندن ردپا از او و اطلاعاتش خواهند شد و این اطلاعات و داده ها قطعا برای سیستم ما مفید است.
- فایل هایی که در آن ها اطلاعات و داده های نفوذ های قبلی ذخیره شده اند نیز منابع بسیار مناسبی هستند.
- اطلاعاتی که از تست های نفوذ به دست می آید قابل استفاده است. در واقع روش هایی که تست کننده ها برای نفوذ به سیستم استفاده می کنند تا بتوانند قابلیت آن را آزمایش کنند نیز همراه با داده هایی است که می توانیم در سیستم خود از آن ها استفاده کنیم.
- و در نهایت داده های موجود در سایت ها مانند www.openpacket.org که می توانند داده های مخرب که قبلا آزمایش شده اند را در اختیار شخص قرار دهند.
اکنون به بررسی نتایج آزمایش روی یکی از انواع درخت که j48 است می پردازیم [۸] .
برای این آزمایش از نرم افزار weka استفاده شده است که از ۳ روش اصلی برای انتخاب ویژگی ها استفاده می کند :
الف – روش (Correlation-based Feature Selection (CFS :
نوعی روش کاهش ویژگیهاست که براساس همبستگی ها پایه گذاری شده است.این الگوریتم نمره بالایی به ویژگیهایی می دهد که دارای وابستگی شدیدتر به کلاس و وابستگی ضعیفی با یکدیگر دارند.
ب- (Information Gain) :
در مورد این روش در همین بخش و در قسمت درخت ID3 توضیحات لازم داده شده است.
ج – (Gain Ratio) :
خاصیت آن حساسیت داشتن به این است که یک ویژگی با چه گستردگی و یکنواختی داده ها را جدا میکند.برای اینکار عبارتی
به صورت زیر تعریف میشود:
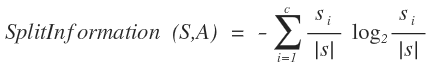
حال با استفاده از این فرمول بهره به صورت زیر تعریف می شود :
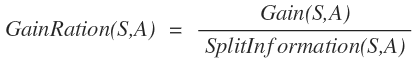
برای این آزمایش نیز از مجموعه داده KDDCup99 استفاده شده که ۱۰ درصد آن شامل ۴۹۴۰۲۱ رکورد است (در مورد این مجموعه داده در آزمایش های بعدی توضیحات بیشتری ارائه شده است.
در این جا به جای ۵ کلاس معمول موجود در مجموعه داده ها از ۱۱ زیر کلاس مربوط به این ۵ کلاس نام برده شده است. که در جدول های بعدی آن ها را مشاهده خواهید کرد.
برای نرمال سازی داده ها که عبارت است از بردن مقادیر ویژگی ها به محدوده [۰,۱] و همه داده های غیر عددی به عددی تبدیل می شوند از رابطه ی زیر استفاده شده که در آن Fi مقدار ویژگی که قرار است نرمال شود ، (min(F و (max(F بزرگترین و کوچکترین مقادیر ویژگی و FNi ویژگی نرمال شده می باشد :
برای ارزیابی دسته ها از معیارهای استاندارد زیر استفاده شده است :
تی پی ۱۷ : این معیار بیانگر تعداد رکوردهایی است که دسته واقعی آن ها مثبت بوده و الگوریتم دسته بندی دسته آن ها را به درستی تشخیص داده است.
اف پی ۱۸ : این معیار بیانگر تعداد رکوردهایی است که دسته واقعی آن ها منفی بوده و الگوریتم دسته بندی به اشتباه دسته آن ها را مثبت تشخیص داده است.
دقت ۱۹ : مبتنی بر دقت دسته بندی است و مبین آن که چه اندازه می توان به خروجی اعتماد کرد.
فراخوانی ۲۰ : برابر تعداد رکوردهای با برچسب مورد نظر است.
در جدول زیر ، زیر کلاس های حملات را که ۱۱ زیر کلاس مشتق شده از ۵ کلاس اصلی است مشاهده می کنید :

و اما دراین جدول مقدار به دست آمده برای هر یک از معیارهای CfS,Gr,IG را مشاهده می کنید :

مقایسه ی کلاس بندی های درست و غلط درخت تصمیم بر اساس ۳ معیار CFS,GR,IG :

و در نهایت مقایسه TP ها در زیر حملات بر اساس ۳ معیار CFS,GR,IG
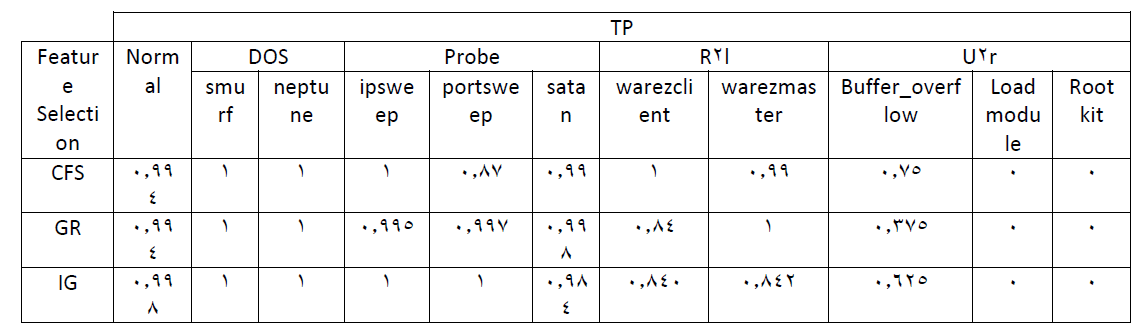
اما برای نتیجه گیری همان طور که مشاهده می شود ، دقت به دست آمده از الگوریتم CFS از دو الگوریتم دیگر بیشتر است و این الگوریتم باعث بهبود بیشتری در الگوریتم درخت J48 نسبت به دو الگوریتم دیگر می شود.










{kind=link}
{kind=link}
دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.