
درحالی که تکنولوژی با سرعتی غیر قابل در حال پیشرفت است، بعضی از اوقات، شائبهها و تصورات اشتباه راهشان را به دایره دانش ما باز میکنند. در این مقاله قصد داریم به مرور برخی از رایجترین اشتباهاتی بپردازیم که مردم هنگام صحبت راجع به سختافزارهای کامپیوتر مرتکب میشوند. در هر مورد، برداشت عمومی اشتباه را تشریح کردهایم و توضیح دادهایم که چرا این ذهنیت غلط است.
۱. مقایسه پردازندهها براساس تعداد هسته و سرعت کلاک
اگر همین فرض را درست بپنداریم و ضمنا تمام مشخصههای دیگر دو پردازنده را کاملا برابر در نظر بگیریم، پردازندهای که ۶ هسته داشته باشد از همان طراحی با ۴ هسته سریعتر است. به همین ترتیب، پردازندهای ۴ گیگاهرتزی از چیپی یکسان با فرکانس ۳ گیگاهرتز سریعتر خواهد بود. ولی وقتی پیچیدگی چیپهای واقعی و مدرن را در بحث دخیل کند، چنین مقایسههایی کاملا بیمعنی میشوند.
برخی وظایف کامپیوتری به فرکانس بالاتر نیاز دارند و برخی هم به هستههای بیشتر. یک پردازنده شاید آنقدر انرژی بیشتری مصرف کند که بهبود پرفورمنس بیارزش جلوه کند. یک پردازنده شاید کش بیشتری نسبت به دیگری داشته باشد، یا یک خط لوله بهینهتر. لیست فاکتورهایی که در این ذهنیت دخیل نشده بسیار بلندبالا است. لطفا هیچوقت پردازندهها را به این شکل با یکدیگر مقایسه نکنید.
۲. سرعت کلاک مهمترین شاخص پرفورمنس است
در ادامهی بحثی که راجع به تصور غلط پیشین مطرح کردیم، لازم است درک کنید که سرعت کلاک همهچیز نیست. دو پردازنده که قیمت حدودا یکسانی داشته و از فرکانس کاری مشابه بهره میگیرند، میتوانند پرفورمنسی کاملا متفاوت از دیگری داشته باشند.
بدون تردید سرعت هسته تاثیر خودش را روی پرفورمنس میگذارند، اما از جایی به بعد، فاکتورهای دیگری به میدان میآیند که تاثیر بزرگتری میگذارند. پردازندهها ممکن است زمان زیادی را صرف منتظر باقی ماندن برای دیگر اجزای سیستم کنند، بنابراین فضای کش و معماری شدیدا مهم است. با اینها میتوان وقت تلق شده را کاهش داد و به پرفورمنس بالاتر در پردازنده رسید.
معماری کلی سیستم میتواند نقشی اساسی در تمام ماجرا ایفا کند. کاملا محتمل است که یک پردازنده کُند که معماری داخلیاش بهتر بهینهسازی شده، دیتای بیشتری را نسبت به یک پردازنده سریع پردازش کند. در طراحیهای جدید، عملکرد بر وات به فاکتوری قابل اتکاتر برای کمیتسنجی پرفورمنس تبدیل شده است.
۳. اصلیترین چیپی که به دستگاه قوت میرساند، پردازنده است

این چیزیست که قبلا کاملا حقیقت داشت، اما با گذشت هر روز، از میزان صحت آن کاسته میشود. بسیاری از ما عادت داریم که بسیاری از کارکردهای مختلف را به «سیپییو» یا «پردازنده» مرتبط بدانیم، اما حقیقت متفاوت است. ترند کنونی در دنیای سختافزار، «پردازش ناهمگن» است و شامل ترکیب کردن بسیاری از المانهای پردازشی درون چیپی واحد میشود.
اگر به صورت کلی صحبت کنیم، چیپ موجود در اکثر سیستمهای دسکتاپ و لپتاپ، پردازنده است. اما در هر دستگاه الکترونیکی دیگری، خبری از پردازنده در معنای سنتیاش نیست و در واقع از «سیستم بر چیپ» (SoC) استفاده شده است.
مادربرد یک کامپیوتر دسکتاپ به فضای کافی برای اتصال انبوهی از چیپهای مختلف که هرکدام وظیفهای خاص دارند دسترسی دارد. اما چنین کاری روی بسیاری از دیوایسهای دیگر مانند موبایلها و تبلتها امکانپذیر نیست. کمپانیهای تکنولوژی، امروز به دنبال افزودن بیشترین کارایی ممکن درون چیپی واحد هستند تا به پرفورمنس بالاتر و بهینگی بیشتر در مصرف انرژی دست پیدا کنند.
علاوه بر پردازنده، سیستم بر چیپ موجود در موبایل شما شامل پردازشگر گرافیکی، رم، انکودر/دیکودر تصویر، مودم، سیستم مدیریت انرژی و دوجین قطعه دیگر نیز میشود. اگرچه به عنوان یک غلط مصطلح میتوانید به تمام اینها به چشم پردازنده نگاه کنید، اما پردازنده یا سیپییو تنها یکی از بخشهای سیستمهای بر چیپ امروزی است.
۴. تکنولوژی گره و ابعاد میتوانند برای مقایسه کارآمد باشند
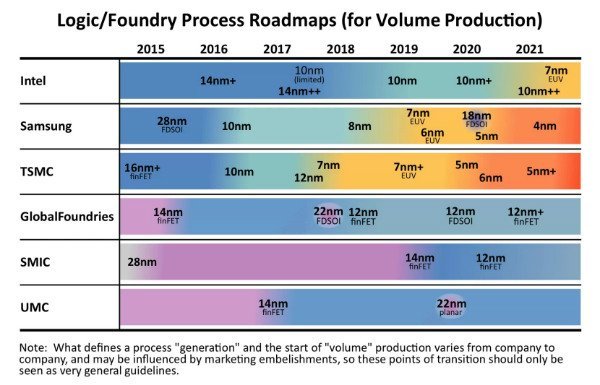
اخیرا اخبار زیادی راجع به تاخیر اینتل در استفاده از تکنولوژی گره (Node) نسل بعدش به گوشمان رسیده است. وقتی یک تولیدکننده چیپ مثل اینتل یا AMD محصولی طراحی میکنند، تولید آن چیپ با یک فرایند خاص صورت میگیرد. رایجترین معیار برای سنجش فرایند، ابعاد ترانزیستورهای بسیار ریزی است که محصول را به وجود میآورند.
این سنجش براساس «نانومتر» انجام میشود و رایجترین فرایندهای تولید، به صورت ۱۴ نانومتر، ۱۰ نانومتر، ۷ نانومتر و ۳ نانومتر انجام میشوند. کاملا منطقی است که بتوانید نسبت به یک چیپ ۱۴ نانومتری، دو برابر ترانزیستور بیشتر را در یک چیپ ۷ نانومتری جای دهید، اما این موضوع لزوما حقیقت ندارد. فاکتورهای زیادی در این موضوع دخیل هستند و بنابراین تعداد ترانزیستورها و به تبع آن، قدرت پردازشی به صورت تصاعدی و همگام با ابعاد تکنولوژی افزایش نمییابد.
یک موضوع مهم دیگر اینست که هیچ سیستم استانداردی برای سنجش به این شکل نداریم. کمپانیهای بزرگ قبلا محصولاتشان را به این شکل میسنجیدند، اما اکنون هرکدام مسیری نسبتا متفاوت نسبت به دیگری در پیش گرفتهاند و سنجش را به طرف اندک متفاوتی انجام میدهند. همه اینها را گفتیم تا برسیم به اینکه ابعاد چیپ نباید هنگام مقایسه معیار باشد. وقتی دو چیپ درون نسلی یکسان داریم، چیپ کوچکتر قرار نیست مزیت چندانی نسبت به دیگری داشته باشد.
۵. مقایسه پردازشگرهای گرافیکی براساس تعداد هسته

هنگام مقایسه پردازنده (سیپییو) و پردازشگر گرافیکی (جیپییو)، بزرگترین تفاوت در تعداد هستههای هرکدام ظاهر میشود. پردازندهها تنها چند هسته بسیار قدرتمند دارند اما پردازشگرهای گرافیکی از صدها یا هزاران هسته با قدرت کمتر تشکیل شدهاند. به این ترتیب، پردازشگرهای گرافیکی میتوانند کارهای بیشتری را به صورت موازی به انجام برسانند.
درست همانطور که پردازنده چهار هستهای یک شرکت میتواند پرفرومنسی بسیار متفاوت از پردازنده چهار هستهای یک شرکت دیگر داشته باشد، این موضوع راجع به پردازشگرهای گرافیکی هم مصداق دارد. هیچ راه خوبی برای مقایسه تعداد هستهها در پردازشگرهای گرافیکی شرکتهای مختلف وجود ندارد. هر تولیدکننده معماری متفاوتی در پیش میگیرد و بنابراین چنین معیارهایی، بیمعنی میشوند.
برای مثال، یک شرکت شاید هستههای کمتر و قابلیتهای بیشتر را ترجیح دهد و شرکتی دیگر مسیر عکس را در پیش بگیرد. البته اگر مشغول مقایسه پردازشگرهای گرافیکی متعلق به یک شرکت و یک خانواده باشید، چنین مقایسهای کاملا قابل قبول است.
۶. فلاپس معیاری صحیح برای سنجش پرفورمنس است
هنگام معرفی و عرضه یک چیپ قدرتمند یا یک ابرکامپیوتر، نخستین چیزی که در تبلیغات روی آن تاکید میشود، خروجی سختافزار براساس «فلاپس» است. فلاپس مخفف «عملیاتهای نقاط شناور بر ثانیه» است و معیاری بر اینکه یک سیستم چه میزان وظیفه را میتواند به انجام برساند.
این معیار به خودی خود بسیار سرراست به نظر میرسد، اما شرکتهای تولیدکننده سختافزار میتوانند با ارقام به گونهای بازی کنند که محصول سریعتر از آنچه واقعا هست به نظر برسد. برای مثال، پردازش ۱.۰ + ۱.۰ به مراتب آسانتر از ۱۲۳۴.۵۶۷۸ + ۸۷۶۵.۴۳۲۱ است. کمپانیها میتوانند محاسبات و میزان دقت آنها را دستکاری کنند تا ارقامشان بهتر از آب درآید.
با چشم دوختن به فلاپس به عنوان تنها معیار پردازش در سیپییو و جیپییو، بیشمار فاکتور دیگر مانند پهنای باند حافظه را نادیده گرفتهاید. این را هم حواستان باشد که کمپانیها میتوانند بنچمارکهایشان را برای سختافزار بهینه کنند تا ارقامی دروغین به دست آید.
۷. آرم چیپ میسازد
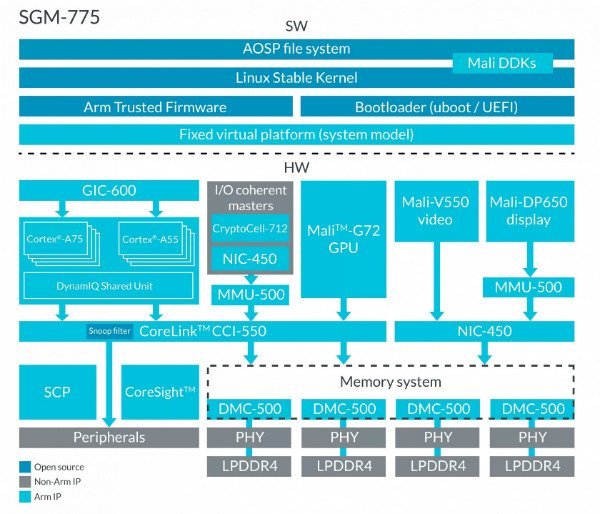
تقریبا تمام سیستمهایی که انرژی کمی مصرف میکنند، تا حدودی قوت گرفته از پردازنده ARM هستند. اما چیزی که دانستناش بسیار مهم است اینکه آرم خودش چیپهای فیزیکی نمیسازد. این شرکت در عوض به طراحی چیپها پرداخته و نقشه ساخت آنها را در اختیار شرکتهای دیگر قرار میدهد تا خودشان به تولید آن روی بیاورند.
برای مثال، سیستم بر چیپ A13 موجود در آیفون، از معماری آرم بهرهمند است اما توسط اپل طراحی شده. مثل اینست که به یک نویسنده یک لغتنامه بدهید و از او بخواهید چیزی بنویسد. نویسنده باید از خط مشی چگونگی استفاده از کلمات پیروی کند، اما در عین حال میتواند راجع به هرچیزی که دلش میخواهد بنویسد..
با فروش لایسنس مالکیتهای معنویاش، شرکت آرم به امثال اپل، کوالکام، سامسونگ و بسیار دیگر اجازه میدهد که از چیپهایش بسته به نیازهایشان استفاده کنند. به این ترتیب، چیپی که برای یک تلویزیون طراحی شده میتواند روی انکود و دیکود تصاویر متمرکز باشد و چیپی که طراحی شده تا داخل ماوس وایرلس قرار بگیرد، روی کاهش مصرف انرژی. و چیپ آرم موجود در ماوس نیازی به پردازشگر گرافیکی یا یک پردازنده قدرتمند ندارد.
از آنجایی که تمام پردازندههای مبتنی بر آرم از هسته مشترکی در طراحی بهره میبرند، قادر به اجرای اپلیکیشنهایی یکسان نیز هستند. بنابراین کار توسعهدهندگان آسان شده و یکپارچگی پلتفرمها دائما افزایش مییابد.
۸. ARM در برابر x86

ARM و x86 دو معماری مبتنی بر دستورالعمل برجسته هستند که چگونگی کارکرد سختافزار کامپیوترها و همینطور چگونگی تعامل با آنها را تعیین میکنند. آرم پادشاه دنیای موبایل و سیستمهای توکار است و x86 بازار لپتاپ، دسکتاپ و سرور را زیر سلطه خود آورده. البته معماریهای دیگری نیز داریم، اما آن معماریها کارکردهای عمومی ندارند.
وقتی راجع به یک معماری مبتنی بر دستورالعمل صحبت میکنیم، در واقع داریم به طراحی داخلی پردازنده اشاره میکنیم. همهچیز مثل ترجمه کردن یک کتاب به زبانی دیگر است. میتوانید ایدههای کلی مطلب را حفظ کنید، اما آنها را به شکلی متفاوت مینویسید. به این ترتیب، بعد از نوشتن یک نرمافزار، میتوانید آن را به گونهای تدوین کنید که روی پردازنده x86 به اجرا درآید یا به گونهای دیگر که روی آرم اجرا شود.
آرم از چند جهت، با x86 تفاوت دارد و به همین خاطر توانسته دنیای موبایل را مال خود کند. برجستهترین تفاوت میان این دو، میزان انعطافپذیری و تکنولوژیهایی است که با خود به ارمغان میآورند. ساخت یک پردازنده آرم مثل این میماند که یک مهندس با اسباببازی لگو بازی کند. آنها میتوانند هر قطعهای که نیاز دارند را برداشته و بهترین پردازنده را برای مصارف خود بسازند. آیا چیپی نیاز دارید که بتواند انبوهی از ویدیوها را پردازش کند؟ میتوانید به سراغ پردازشگر گرافیکی قدرتمندتر بروید. نیاز به امنیت و کدگذاری دارید؟ میتوانید از شتابدهندههای مخصوص بهره بگیرد.
تمرکز آرم بر فروش لایسنس تکنولوژی به جای فروش چیپهای فیزیکی، اصلیترین دلیل موفقیت معماری آنها بوده است. اینتل و AMD در این حوزه بسیار دیر عمل کردند و خلایی به وجود آوردند که تبدیل به فرصتی برای آرم شد.
حالا که صحبت از اینتل شد، این شرکت عمدتا از معماری x86 استفاده میکند و گرچه آنها سازندهاش هستند، اما AMD هم به استفاده از آن روی آورده. اگر جایی چشمتان به عبارت x86-64 خورد، صرفا به ورژن ۶۴ بیتی x86 اشاره شده است. اگر به صورت مداوم از ویندوز استفاده کنید، احتمالا برایتان این سوال پیش آمده که چرا دو فولدر به نامهای «Program Files» و «Program Files (x86)» داریم. موضوع به این خاطر نیست که نخستین فولدر از x86 استفاده نمیکند، موضوع فقط اینست که این فولدر برخلاف فولدر دوم، ۳۲ بیتی است.
یک برداشت اشتباه دیگر هنگام مقایسه آرم و x86، نسبت عملکرد آنهاست. گفتنش سخت نیست که پردازندههای x86 همواره سریعتر از پردازندههای آرم هستند و به همین خاطر، هیچوقت پردازندههای آرم را در سیستمهای بسیار قدرتمند نمیبینیم. اما این مقایسه منصفانه نیست. تمام فلسفه طراحی آرم، تمرکز بر بهینگی و کاهش مصرف انرژی است. آرم به x86 اجازه موفقیت در بازار سیستمهای پیشرفته را داده چون اصلا در آن بازار فعالیتی نمیکند. درحالی که اینتل و AMD روی بیشینه پرفورمنس با x86 متمرکز هستند، آرم پرفورمنس را به بیشترین میزان به ازای هر وات میرساند.
۹. پردازشگرهای گرافیکی سریعتر از پردازندهها هستند

طی چند سال اخیر، شاهد افزایش چشمگیر پرفورمنس و نفوذ پردازشگرهای گرافیکی بودهایم. بسیاری از وظایف کامپیوتری که قبلا توسط پردازنده انجام میشدند حالا زیر دست پردازشگر گرافیکی قرار میگیرند تا از مزیت پردازش موازی برخوردار شوند. به این ترتیب، در وظایفی که نیازمند پردازش موازی چندین کار کوچک هستند، جیپییو سریعتر از سیپییو ظاهر میشود. اما این موضوع چیزی نیست که همواره مصداق داشته باشد و به همین خاطر، هنوز به پردازندهها نیاز داریم.
برای استفاده صحیح از سیپییو یا جیپییو، توسعهدهنده باید کد خود را با کامپایلرها و رابطهای برنامهنویسی خاص بهینهسازی کند. هستههای پردازشی داخلی یک جیپییو که تعدادشان میتواند به هزاران عدد برسد، در قیاس با هستههای پردازنده بسیار ساده هستند. این هستهها طراحی شدهاند تا وظایف کوچکی را دوباره و دوباره به انجام برسانند.
هستههای سیپییو از طرف دیگر برای مجموعهای از عملیاتهای پیچیده طراحی شدهاند. برای برنامههایی که نمیتوانند به صورت موازی پردازش شوند، پردازنده همواره گزینهای بهتر است. با کامپایلر مناسب، از لحاظ فنی میتوان کدی که برای پردازنده نوشته را روی پردازشگر گرافیکی به اجرا در آورد و بالعکس، اما مزایای واقعی تنها زمانی حاصل میشوند که برنامه برای پلتفرم مقصد بهینهسازی شده باشد. اگر قرار باشد صرفا به قیمتگذاریها نگاه کنیم، گرانقیمتترین پردازندههایی میتوانند ۵۰ هزار دلار باشند، اما قدرتمندترین پردازشگرهای گرافیکی تنها نصف این مقدار قیمتگذاری شدهاند. در مجموع، سیپییوها و جیپییوها هرکدام در حوزه خود قدرتمند تلقی میشوند و هیچکدام لزوما از دیگری سریعتر نیست.
۱۰. پردازندهها همواره سریعتر و سریعتر میشوند

یکی از شناختهشدهترین قواعد صنعت تکنولوژی، قانون مور است. براساس این قانون، تعداد ترانزیستورهای موجود در هر چیپ، هر دو سال یکبار حدودا دو برابر میشود. این قانون در ۴۰ سال اخیر همواره صحت داشته است، اما اکنون به نقطهای رسیدهایم که این رشد تصاعدی دیگر مثل سابق اتفاق نمیافتد.
میتوانیم با خود فکر کنیم که اگر نمیتوانیم ترانزیستورهای بیشتر را درون چیپ جای دهیم، شاید بتوانیم چیپهایی بزرگتر بسازیم. اما محدودیت اصلی، افزایش قدرت چیپ و در عین حال، از بین بردن حرارتی است که تولید میکند. چیپهای مدرن نیازمند جریانی معادل صدها آمپر هستند و صدها وات حرارت نیز تولید میکنند.
سیستمهای ارائه انرژی و خنک کننده امروزی با محدودیتهای فراوانی مواجه هستند و به همین خاطر نمیتوان خیلی ساده چیپهایی بزرگتر ساخت. پس اگر نمیتوانیم چیپهای بزرگتر بسازیم، نمیتوانیم ترانزیستورهای روی چیپ را کوچکتر کنیم و پرفورمنس را بالا ببریم؟ این همان چیزی است که برای مدتها ذهن فعالان تکنولوژی را به خود مشغول کرده و برای چند دهه هم انجام شده. اما حالا در کوچکتر کردن ترانزیستورها به مشکل خوردهایم.
با استفاده از فرایندهای ۷ نانومتری و ۳ نانومتری، اثرات کوانتومی تبدیل به مشکل میشوند و ترانزیستورها به درستی رفتار نمیکنند. البته هنوز فضایی کمابیش برای کاهش هرچه بیشتر ابعاد ترانزیستورها وجود دارد، اما اگر دست به ابداعاتی تازه نزنیم، دیگر نمیتوانیم آنها را از این کوچکتر کنیم. پس اگر نمیتوانیم چیپهای بزرگتر بسازیم و اگر نمیتوانیم ترانزیستورها را کوچکتر کنیم، آیا امکان دارد که ترانزیستورهای فعلی را سریعتر کنیم؟ این هم حوزهای است که در گذشته منافع زیادی برایمان به همراه داشته اما حالا دارد به بنبست میخورد.
درحالی که سرعت پردازنده طی نسلهای اخیر افزایش یافته، برای نزدیک به یک دهه در رنج فرکانس ۳ الی ۵ گیگاهرتز گیر کردهایم. این به خاطر ترکیبی از فاکتورهای مختلف است. مشخصا یکی از دلایل عدم افزایش فرکانس کاری، مصرف انرژی بالاتر است. اما دلیل اصلی را میتوان در محدودیتهای ترانزیستورهای کوچکتر و همینطور قوانین فیزیک جستجو کرد.
وقتی ترانزیستورهای کوچکتر میسازیم، باید سیمهایی کوچکتر نیز بسازیم که آنها را به یکدیگر متصل نگه دارند که این هم مقاومت را افزایش میدهد. ما به صورت سنتی توانستهایم سرعت ترانزیستورها را از طریق کاهش فاصله میان قطعاتشان روی چیپ افزایش دهیم، اما برخی از قطعات ترانزیستورهای امروزی تنها اندازه یک یا دو اتم از یکدیگر فاصله دارند. بنابراین فضای چندانی برای بهبود وجود ندارد.
۱۰ Big Misconceptions About Computer Hardware
With technology advancing so rapidly around us, sometimes misconceptions can work their way into our common understanding. In this article, we’ll take a step back and go over some of the most common things people get wrong when talking about computer hardware. For each one, we’ll list the common fallacy as well as why it is not accurate.
#۱ You can compare CPUs by core count and clock speed
If you’ve been around technology for a while, at some point you may have heard someone make the following comparison: “CPU A has 4 cores and runs at 4 GHz. CPU B has 6 cores and runs at 3 GHz. Since 4*4 = 16 is less than 6*3 = 18, CPU B must be better”. This is one of the cardinal sins of computer hardware. There are so many variations and parameters that it is impossible to compare CPUs this way.
Taken on their own and all else being equal, a processor with 6 cores will be faster than the same design with 4 cores. Likewise, a processor running at 4 GHz will be faster than the same chip running at 3 GHz. However, once you start adding in the complexity of real chips, the comparison becomes meaningless.

There are workloads that prefer higher frequency and others that benefit from more cores. One CPU may consume so much more power that the performance improvement is worthless. One CPU may have more cache than the other, or a more optimized pipeline. The list of traits that the original comparison misses is endless. Please never compare CPUs this way.
#۲ Clock speed is the most important indicator of performance
Building on the first misconception, it’s important to understand that clock speed isn’t everything. Two CPUs in the same price category running at the same frequency can have widely varying performance.
Certainly core speed has an impact, but once you reach a certain point, there are other factors that play a much bigger role. CPUs can spend a lot of time waiting on other parts of the system, so cache size and architecture is extremely important. This can reduce the wasted time and increase the performance of the processor.
The broad system architecture can also play a huge part. It’s entirely possible that a slow CPU can process more data than a fast one if its internal architecture is better optimized. If anything, performance per watt is becoming the dominant factor used to quantify performance in newer designs.
#۳ The main chip powering your device is a CPU
This is something that used to be absolutely true, but is becoming increasingly less true every day. We tend to group a bunch of functionality into the phrase “CPU” or “processor” when in reality, that’s just one part of a bigger picture. The current trend, known as heterogeneous computing, involves combining many computing elements together into a single chip.

Generally speaking, the chips on most desktops and laptops are CPUs. For almost any other electronic device though, you’re more than likely looking at a system on a chip (SoC).
A desktop PC motherboard can afford the space to spread out dozens of discrete chips, each serving a specific functionality, but that’s just not possible on most other platforms. Companies are increasingly trying to pack as much functionality as they can onto a single chip to achieve better performance and power efficiency.
In addition to a CPU, the SoC in your phone likely also has a GPU, RAM, media encoders/decoders, networking, power management, and dozens more parts. While you can think of it as a processor in the general sense, the actual CPU is just one of the many components that make up a modern SoC.
#۴ Technology node and feature size are useful for comparing chips
There’s been a lot of buzz recently about Intel’s delay in rolling out their next technology node. When a chip maker like Intel or AMD designs a product, it will be manufactured using a specific technology process. The most common metric used is the size of the tiny transistors that make up the product.
This measurement is made in nanometers and several common process sizes are 14nm, 10nm, 7nm, and 3nm. It would make sense that you should be able to fit two transistors on a 7nm process in the same size as one transistor on a 14nm process, but that’s not always true. There is a lot of overhead, so the number of transistors and therefore processing power doesn’t really scale with the technology size.

Source: IC Insights
Another potentially larger caveat is that there is no standardized system for measuring like this. All the major companies used to measure in the same way, but now they have diverged and each measure in a slightly different way. This is all to say that the feature size of a chip shouldn’t be a primary metric when doing a comparison. As long as two chips are roughly within a generation, the smaller one isn’t going to have much of an advantage.
#۵ Comparing GPU core counts is a useful way to gauge performance
When comparing CPUs to GPUs, the biggest difference is the number of cores they have. CPUs have a few very powerful cores, while GPUs have hundreds or thousands of less powerful cores. This allows them to process more work in parallel.
Just like how a quad core CPU from one company can have very different performance than a quad core CPU from another company, the same is true for GPUs. There is no good way to compare GPU core counts across different vendors. Each manufacturer will have a vastly different architecture which makes this type of metric almost meaningless.

For example, one company may choose fewer cores but add more functionality, while another may prefer more cores each with reduced functionality. However, as with CPUs, a comparison between GPUs from the same vendor and in the same product family is perfectly valid.
#۶ Comparing FLOPs is a useful way to gauge performance
When a new high-performance chip or supercomputer is launched, one of the first things advertised is how many FLOPs it can output. The acronym stands for floating point operations per second and measures how many instructions can be performed by a system.
This appears straightforward enough, but of course, vendors can play with the numbers to make their product seem faster than it is. For example, computing 1.0 + 1.0 is much easier than computing 1234.5678 + 8765.4321. Companies can mess with the type of calculations and their associated precision to inflate their numbers.
Looking at FLOPs also only measures raw CPU/GPU computation performance and disregards several other important factors like memory bandwidth. Companies can also optimize the benchmarks they run to unfairly favor their own parts.
#۷ ARM makes chips
Almost all low-power and embedded systems are powered by some form of ARM processor. What’s important to note though is that ARM doesn’t actually make physical chips. Rather, they design the blueprints for how these chips should operate, and let other companies build them.
For example, the A13 SoC in the latest iPhone uses the ARM architecture, but was designed by Apple. It’s like giving an author a dictionary and having them write something. The author has the building blocks and has to adhere to guidelines about how the words can be used, but they are free to write whatever they want.

By licensing out their intellectual property (IP), ARM allows Apple, Qualcomm, Samsung, and many others to create their own chips best suited to their own needs. This allows a chip designed for a TV to focus on media encoding and decoding, while a chip designed to go into a wireless mouse will focus on low power consumption.
The ARM chip in the mouse doesn’t need a GPU or a very powerful CPU. Because all processors based on ARM use the same core set of designs and blueprints, they can all run the same apps. This makes the developer’s job easier and increases compatibility.
#۸ ARM vs. x86
ARM and x86 are the two dominant instruction set architectures that define how computer hardware works and interacts. ARM is the king of mobile and embedded systems, while x86 controls the laptop, desktop, and server market. There are some other architectures, but they serve more niche applications.
When talking about an instruction set architecture, that refers to the way a processor is designed on the inside. It’s like translating a book into another language. You can convey the same ideas, but you just write them out in a different way. It’s entirely possible to write a program and compile it one way to run on an x86 processor and another way to run on ARM.

ARM has differentiated from x86 in several key ways, which have allowed them to dominate the mobile market. The most important is their flexibility and broad range of technology offerings. When building an ARM CPU, it’s almost as if the engineer is playing with Legos. They can pick and choose whatever components they want to build the perfect CPU for their application. Need a chip to process lots of video? You can add in a more powerful GPU. Need to run lots of security and encryption? You can add in dedicated accelerators. ARM’s focus on licensing their technology rather than selling physical chips is one of the main reasons why their architecture is the most widely produced. Intel and AMD on the other hand have stagnated in this area which created the vacuum that ARM took control of.
Intel is most commonly associated with x86 and while they did create it, AMD processors run the same architecture. If you see x86-64 mentioned somewhere, that’s just the 64-bit version of x86. If you’re running Windows, you may have wondered why there is a “Program Files” and a “Program Files (x86)”. It’s not that programs in the first folder don’t use x86, it’s just that they are 64-bit while programs in “Program Files (x86)” are 32-bit.
One other area that can cause confusion between ARM and x86 is in their relative performance. It’s easy to think that x86 processors are just always faster than ARM processors and that’s why we don’t see ARM processors in higher-end systems. While that is usually true (up until now), it’s not really a fair comparison and it’s missing the point. The whole design philosophy of ARM is to focus on efficiency and low-power consumption. They let x86 have the high-end market because they know they can’t compete there. While Intel and AMD focus on maximum performance with x86, ARM is maximizing performance per Watt.
#۹ GPUs are faster processors than CPUs
Over the past few years, we have seen a huge rise in GPU performance and prevalence. Many workloads that were traditionally run on a CPU have moved to GPUs to take advantage of their parallelism. For tasks that have many small parts that can be computed at the same time, GPUs are much faster than CPUs. That’s not always the case though, and is the reason we still need CPUs.

In order to make proper use of a CPU or GPU, the developer has to design their code with special compilers and interfaces optimized for the platform. The internal processing cores on a GPU, of which there can be thousands, are very basic compared to a CPU. They are designed for small operations that are repeated over and over.
The cores in a CPU, on the other hand, are designed for a very wide variety of complex operations. For programs that can’t be parallelized, a CPU will always be much faster. With a proper compiler, it’s technically possible to run CPU code on a GPU and vice-versa, but the real benefit only comes if the program was optimized for the specific platform. If you were to just look at price, the most expensive CPUs can cost $۵۰,۰۰۰ each while top-of-the-line GPUs are less than half of that. In summary, CPUs and GPUs both excel in their own areas and neither is necessarily faster than the other outright.
#۱۰ Processors will always keep getting faster
One of the most famous representations of the technology industry is Moore’s Law. It is an observation that the number of transistors in a chip has roughly doubled every 2 years. It has been accurate for the past 40 years, but we are at its end and scaling isn’t happening like it used to.
If we can’t add more transistors to chips, one thought is that we could just make them bigger. The limitation here is getting enough power to the chip and then removing the heat it generates. Modern chips draw hundreds of Amps of current and generate hundreds of Watts of heat.

Today’s cooling and power delivery systems are struggling to keep up and are close to the limit of what can be powered and cooled. That’s why we can’t simply make a bigger chip.
If we can’t make a bigger chip, couldn’t we just make the transistors on the chip smaller to add more performance? That concept has been valid for the past several decades, but we are approaching a fundamental limit of how small transistors can get.
With new 7nm and future 3nm processes, quantum effects start to become a huge issue and transistors stop behaving properly. There’s still a little more room to shrink, but without serious innovation, we won’t be able to go much smaller. So if we can’t make chips much bigger and we can’t make transistors much smaller, can’t we just make those existing transistors run faster? This is yet another area that has given benefits in the past, but isn’t likely to continue.
While processor speed increased every generation for years, it has been stuck in the 3-5GHz range for the past decade. This is due to a combination of several things. Obviously it would increase the power usage, but the main issue again has to do with the limitations of smaller transistors and the laws of physics.
As we make transistors smaller, we also have to make the wires that connect them smaller, which increases their resistance. We have traditionally been able to make transistors go faster by bringing their internal components closer together, but some are already separated by just an atom or two. There’s no easy way to do any better.
Putting all of these reasons together, it’s clear that we won’t be seeing the kind of generational performance upgrades from the past, but rest assured there are lots of smart people working on these issues.


{kind=link}
{kind=link}